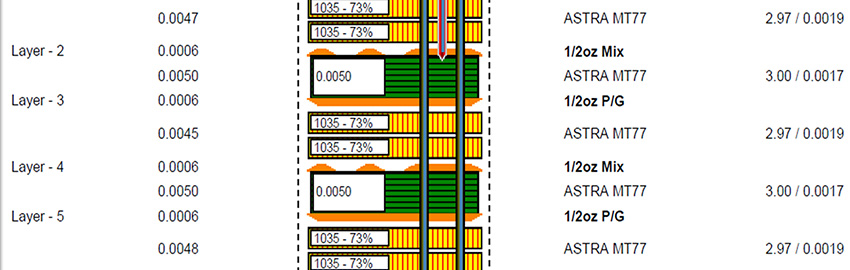
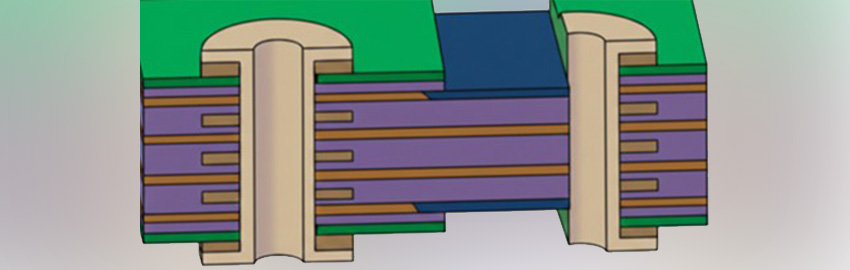
Segmenting the stencil layer improves solder coverage.
Quad-flat-no-lead (QFN) components (also known as MLF or micro lead-frame) used to cause a lot of problems a few years ago, if the number of blog posts covering the subject is evidence.1
Can I use my own blog as cited evidence to justify my own conclusion? It probably is bad form, but I’m doing it anyway. Interestingly, if you look up “citations” in Wikipedia, the entry (as of this writing) has a note indicating that the article on citations has insufficient online citations. Hmmm.
Anyway, it seems the industry is catching up with the proper manufacturing methodology for use of the technology. It’s important enough, though, that it bears repeating. The key to successful QFN and DFN manufacturing is in the solder paste stencil pattern. Consult the datasheet for the part, but if you can’t find the datasheet, or if it doesn’t cover the stencil layer, use the window pane technique, or “segmenting”, for the stencil layer when making the library part for the CAD software.
If the full thermal pad area is left fully open, the likely result will be too much solder in that area. The part will ride higher than it should and may very well float too high for all of the pads on the side to connect. (See the top drawing in Figure 1.)
Instead, shoot for 50% to 75% paste coverage by segmenting the stencil (Figure 2). That’ll ensure the center pad and the side signal lands will be at the same level. It will pay off in much better yields and reliability.
Duane Benson is marketing manager at Screaming Circuits (screamingcircuits.com); This email address is being protected from spambots. You need JavaScript enabled to view it.. His column appears bimonthly.
The age-old technology is seeing new life in medical and other applications.
Old technologies never die; they just get new names. Flex circuits have been around for many years in the IC packaging business and have been called almost as many names. In the early days, it was tape automated bonding (TAB). General Electric called it Mimi-Mod; Motorola called it Spider, and the first patent (despite an IP spat) was granted to a woman engineer, Frances Hugle, of Hugle Industries in 1969. TAB became famous with its use for driver ICs, connecting them to the ITO pattern on the glass LCD panel. The tape was Sn-plated, and issues with tin whiskers led Japanese companies such as Shindo Denshi to tackle the problem using an annealing process and nitrogen storage before bonding. Later the technology was called tape carrier package (TCP). Over time die were even mounted on the flex circuit without a bonding window, and the concept became chip-on-film (CoF).
In the 1980s, National Semiconductor licensed its TapePack technology to a several companies. This package also used TAB bonding. Kenzo Hatada at Matsushita developed a process called TB-TAB where a gold bump was placed on the TAB tape and die connected. Memory could be stacked this way. Other companies also worked on versions of stacked memory with flex circuits, including Thomson-CSF (now Thales). A 3-D package using flex is still in production today at 3D Plus, the spinoff from Thomson-CSP founded by Christian Val.
TCP was also used in Apple’s Newton. LSI’s ASIC was TAB-bonded in the package. The effort was the result of close cooperation among engineers with LSI, Sharp and Apple.
In the 1990s, flex became popular. A few ex-engineers (Tom DiStefano and Igor Khandros) from IBM got together and formed a company called IST. They came up with an idea to use flex circuit to make a really small chip-size package called a µBGA. They filed some patents, moved to California, and gave the company the name Tessera. Really, it was flex circuit. IC bond pads were connected to an array of bump connections on flex. Some DRAMs still ship in this type of package because this flex circuit structure provides excellent electrical performance. NEC developed a CSP using a flex circuit and called it a fine-pitch ball grid array (FPBGA). Nitto Denko used its ASMAT file with a z-axis conductive flex circuit material to form its Resin-Molded CSP. GE also applied its multichip module technology where flex was used for the redistribution layer to single-chip packages and called it a thin zero outline package.
Around 1995, Texas Instruments also came up with a CSP using flex circuit in order to make a low profile package called µSTAR BGA. This package is still in production. While these configurations were all single chip, flex circuit substrates were used for stacked die CSPs by Sharp, Fujitsu, NEC and many others because they provided an ultra-thin substrate that enabled a reduction in z-height. Tessera developed a folded, stacked package and Intel licensed it. This folder flex used a two-metal layer tape and was in production for many years until the business was sold to Marvell and the product reached end-of-life. Flex circuit substrate CSPs are being replaced by thin-core laminate substrates for new designs, but still accounted for approximately 1.5 billion packages in 2009.
Mainly driven by electrical performance, TAB tape was also used for large-size BGAs (TBGAs). Both TAB bonding and wire bonding have been used to interconnect pads on the die to flex circuit substrates. Semiconductor companies shipping TBGAs include Fujitsu, Freescale Semiconductor, NEC, Renesas and Toshiba. As rigid laminate materials have improved, TBGA volumes have declined.
While flex’s popularity seems waning in some IC packaging applications, it is increasingly popular in medical electronics. Hearing aids, catheters, imaging systems, some implantable devices, and other products depend on flex to meet space, performance and density requirements. The digital hearing aid is a good example. Flex is often a folded product, and depending on the number of folds, the overall length of the flex can be more than 1.5 cm with one or multiple arms and a width of 5 to 10 mm (Figure 1).
Flex is expected to play an important role in wearable electronics. One of a number of research programs underway in Europe, TIPS is targeted at medical and health monitoring both for implanted and non-implanted medical devices, sensors, and portable and wearable electronics systems. A folded thin flex module containing a hearing aid flip-chip set has been demonstrated.1
Flex already is playing a role in the embedded component business for a multitude of applications. The Imbera technology, known as Integrated Module Board (IMB), which embeds active and passive die in laminate structures, has been extended to flex circuits. A number of companies have developed processes incorporating resistors in flex circuit material, including Asahi Chemical Research Laboratory, DuPont, Ohmega Technologies, Ticer Technologies, and Endicott Interconnect. Buried capacitors in flex are offered by Oak-Mitsui Technologies, 3M Electronics, DuPont and Hitachi Chemical.
The flexibility of flex circuits will enable it to find applications in a variety of future products. New and exciting possibilities are expected of a technology that has been around a long time.
Reference 1. G. Kunkel, “Ultra-flexible and Ultra-thin Embedded Medical Devices on Large Area Panels, “ European Semantic Technology Conference, September 2010.
E. Jan Vardaman is president of TechSearch International (techsearchinc.com); This email address is being protected from spambots. You need JavaScript enabled to view it.. Her column appears bimonthly.
San Jose showed once again why it’s the epicenter for printed circuit design.
The outside temperature hit 103°F in the Silicon Valley, but inside the action at the PCB West trade show was even hotter.
Attendance at PCB West in late September was up markedly – 26% for the exhibition and 35% for the conference. Overall attendee registration jumped 20.4%, as the industry responded with vigor to the strong lineup of exhibitors, complemented by an outstanding technical program.
Signal integrity remained a major area of interest, although during the PCB Designers Roundtable – cosponsored by the good folks from the Silicon Valley Designers Council chapter – it was revealed that perhaps one-third of designers don’t actually perform SI analysis. (It’s left for someone else.) Proponents on hand, including the ubiquitous Rick Hartley, who taught several classes during the three-day technical conference, stressed that all designers should perform some level of SI. Also revealed: A large percentage of designers continue to manually route their boards, despite evidence showing autorouters could save time. Whether they do so because they are trying to protect their jobs is certainly understandable, but the notion that autorouting could free up resources that could then be used in other areas (such as SI analysis) bears consideration.
Many of the technical sessions that accompanied the trade show were packed, as designers and process engineers took advantage of the free sessions to glean valuable information on reducing layer counts, thermal management, post-assembly cleaning, and CAD-CAM. In one eye-opening presentation, Don Trenholm of Custom Analytical Services literally ran out of time showing slides of various counterfeited components.
On the show floor, several companies either showed new tools and services or discussed pending upgrades.
National Instruments (ni.com) is releasing an upgrade to its MultiSim and Ultiboard suite for design optimization, schematic capture and SPICE simulation. The new release will include upgrades to handle power components, simulation improvements, IPC land patterns, more user-defined functionality, and stronger encryption. “We are starting to bridge the point where we can do a design, the virtual testing and then see how they compare,” general manager Vince Accardi explains. (For NI, the show also marked a changing of the guard of sorts, as Accardi and longtime product manager engineer Bavesh Mistry have been promoted, and former R&D engineer Natasha Baker is taking over the latter’s role as PME.)
Mentor Graphics (mentor.com) touted its latest FloTherm thermal analysis tool, which helps designers identify thermal bottlenecks and shortcuts where new thermal paths would cool the design faster. The tool can perform a detailed simulation of the package itself, and users can overlay the component thermal model (which allows black box simulation) to simulate the package and complete PCB.
As long as there have been CAD tools, there have been translation problems. Not surprisingly, then, several companies showed various flavors of ECAD translators. SFM Technology’s PackageWright (packagewright.com) tool combines an online database of thousands of package models with footprint generation capability and an ECAD-MCAD library synchronization service. The tool supports flow from MCAD-ECAD and back.
AcAe (acae.com) drew a crowd with its DART ECAD conversion tool. Noting that the EDIF schematic and netlist translator format was launched more than 25 years ago, AcAe president Bill Basten said the biggest problem designers and manufacturers now face is that many translators simply don’t work. “The schematics don’t match; they can’t do constraints; they leave things out.” DART, he says, which runs on Linux and Windows, verifies netlists and copper, and permits use of libraries and symbols, provided they are similar.
PCB West has an emerging assembly bent to it, highlighted by several tracks on counterfeit component identification and mitigation, post-assembly cleaning and test strategies. Classes on thermal management and layer reduction were also popular.
By providing PCB engineers, designers, fabricators, assemblers and managers with the most targeted conference in the industry, PCB West proved the market for board-level shows isn’t dead after all. Full details regarding the conference and exhibition are available at pcbwest.com.
Following this year’s successful show, PCB West will return to the Santa Clara (CA) Convention Center Sept. 27-29, 2011.
Mike Buetow is editor-in-chief of CIRCUITS ASSEMBLY and PCD&F; This email address is being protected from spambots. You need JavaScript enabled to view it..
Measuring differential pair loss requires both lines to calculate the attenuation.
Whether a high-speed serial link channel works is just as dependent on the losses in the channel as its differential impedance. It’s not enough to just meet an impedance spec and verify it using a test coupon. In many applications, it is also important to meet a loss spec and verify the attenuation of traces in a test coupon.
Measuring the signal-ended impedance of a trace in a test coupon is easy. All fab shops understand how to do this with a TDR. It is tempting to think that if you use the same line in a single-ended line or in a differential pair, a line is a line, and all you have to do is measure it once to know the differential impedance. After all, the other line in the pair isn’t even touching its partner.
Unfortunately, while the proximity of the other trace in a differential pair will not change its single-ended impedance, the proximity will strongly affect the differential impedance of the pair.
Just measuring the single-ended impedance of one line in a differential pair, either as an isolated line or when in the differential pair, is no indication of the differential impedance. The measurement can be off by as much as 10% for tightly coupled microstrip or stripline pairs. You have to go the extra step to measure the differential impedance using a dual TDR.
Likewise, you cannot accurately measure the loss in a differential pair by just measuring the loss of one of the lines, or of an isolated version of that line. The coupling between the lines will affect the measured attenuation.
Figure 1 is a comparison of the differential insertion loss of a differential stripline pair, and of just one of the lines as a single-ended line stripline.
We usually define the losses in a uniform transmission line as the attenuation, measured in dB. Since the loss, in dB, increases linearly with the length of the line, it is often more common to use the metric of the attenuation per length, measured in dB/inch. For example, Intel recommends differential pairs used in PCIe III interconnects have a loss less than 0.78 dB/inch at 4 GHz.
In addition to geometry features, raw material and processing conditions will affect loss in a differential pair, making it necessary to measure test coupons to verify the attenuation per length of differential pairs on the board.
Unfortunately, measuring the attenuation of a single line that may be isolated or part of a differential pair will provide a different attenuation than the actual differential impedance of the pair. The coupling between the lines will affect the differential attenuation. Here’s why:
Loss arises from conductor loss and dielectric loss. In stripline, attenuation from the dielectric loss is independent of coupling. If there were no conductor loss, measuring the attenuation of an isolated single-ended line or one line in a differential pair would give the same attenuation as the attenuation of the differential pair. The attenuation from the conductor loss depends on the coupling in two ways. The attenuation is not due to just the series resistance alone, but the ratio of the series resistance to the differential impedance.
If the line width is kept fixed, and the two lines in a differential pair brought closer together, the differential impedance will decrease. Even if the series resistance were to remain constant, the attenuation would increase because the differential impedance decreased.
To complicate this further, the proximity of the two lines in the differential pair changes the current distribution in the conductors, changing the series resistance. Surprisingly, the series resistance goes down with tighter coupling as more of the return currents overlap and cancel. The current crowding in the signal traces does not start to increase the signal path series resistance until the spacing between the lines is much less than a line width.
The combination of these two effects means the attenuation will be higher in a differential pair than if measured as single-ended lines. This is all the more reason for all suppliers and users of high-speed differential channels to begin implementing a process to measure the attenuation of differential pairs for all high-performance boards.
Eric Bogatin, Ph.D., is a consultant and founder of Be The Signal (bethesignal.com); This email address is being protected from spambots. You need JavaScript enabled to view it.. His column runs periodically.
Written by Byron Blackmore, John Parry and Robin Bornoff
Category: 2010 Issues
New 3D thermal quantities help designers address thermal problems as they arise.
Electronics thermal management is the discipline of designing electronics systems to facilitate the effective removal of heat from the active surface of integrated circuits to a colder ambient environment. In doing so, heat passes from the package both directly to the surrounding air and via the PCB on which the IC is mounted. The PCB and, to a lesser extent, the surrounding air thermally couple the various heat sources.
Heat coupling increases as components and PCBs become smaller and more powerful. Designers must take remedial action to bring all components within their respective thermal specifications, but this step is becoming more challenging and constrained, even when preventative measures are taken early in the design process.
For the past 20 years, computational fluid dynamics (CFD) techniques have provided 3D thermal simulations that include views of the air-side heat transfer that predict component junction and case temperatures under actual operating conditions. Designers routinely use these predicted temperatures to judge thermal compliance simply by comparing the simulated temperatures to maximum rated operating temperatures. If the operating temperature exceeds the maximum rated value, there will be at least a potential degradation in the performance of the packaged IC, and at worst, an unacceptable risk of thermo-mechanical failure.
Simulated 3D temperature and flow fields provide detailed and useful information, but give little physical insight into why the temperature field is the way it is. Examining heat flux vectors can yield some insight into the heat removal paths. But the heat flux vector direction and magnitude data do not provide a measure of the ease with which heat leaves the system. Nor do they provide insight as to where and how the heat flux distribution might be better balanced or reconfigured to improve performance.
How easily heat passes from the various sources to the ambient will determine the temperature rise at the sources and all points in between. Heat flow paths are complex and three-dimensional, carrying portions of the heat with varying degrees of ease. Paths that carry a lot of heat but offer large resistances to that heat flow represent bottlenecks. A redesign can relieve these bottlenecks, permitting heat to pass to the ambient more easily and reducing temperature rises along the heat flow path all the way back to the heat source. In addition, there may be unrealized opportunities to introduce new heat flow paths that would permit heat to pass to colder areas and out to the ambient. So a redesign informed by the right information can do more than alleviate bottlenecks; it can also introduce thermal “shortcuts” to bypass them.
Sans a way to identify such thermal bottlenecks and shortcut opportunities within a design, PCB design teams have faced a stark choice. Either bring in thermal experts to resolve thermal problems, or rely on being able to add heat sinks later. Lacking direction from the simulation results as to appropriate remedial action, thermal engineers have traditionally relied on experience and engineering judgment to guide their search for design improvements. Today their work is often supplemented by design of experiments and automatic design optimization capabilities within the thermal simulator. Such approaches take time.
An innovative way to view the thermal behavior of a populated PCB uses two new 3D thermal quantities aptly known as the BottleNeck (Bn) Number and the ShortCut (Sc) Number that, taken together, guide designers to take appropriate, targeted remedial action to address thermal problems as they are encountered.
Vectors, Bottlenecks and Shortcuts
Heat flow can be defined in terms of a heat flow through a given cross-sectional area. This measure is known as a heat flux. The presence of a heat flux vector will always be accompanied by a temperature gradient vector. The temperature gradient field is taken to be an indicator of conductive thermal resistance as, for a given heat flux, the greater the temperature gradient is, the larger the thermal resistance will be.
The dimensionalized Bn number is the dot product of these two vector quantities. At each point in space (Figure 1) where there exists a heat flux vector and temperature gradient vector, the Bn scalar at that point is calculated as:
This is not always true, of course, especially for multiple heat sources (as found on almost every PCB) where heat flow topologies for widely separated components can be quite independent of each other.
To illustrate how this process works in practice, consider a typical air-cooled PCB (Figure 2). The central BGA has highest temperature rise above specification, followed by the two TO-263s above and to the right.
Though it depicts the same PCB, Figure 3 is not the same kind of thermal view as Figure 2. Instead, it shows the Sc number distribution mapped at a point just above the tops of the packages on the board. Although in Figure 3 the largest Sc numbers are associated with the hottest component, this is not always the case. A component might be hot due to the temperature of the surrounding air, rather than its own internal power dissipation. In the case of this centrally located BGA, the large Sc values on its top surface indicate relatively efficient convective heat transfer locally. Therefore, the obvious remedial design action is to add a heat sink. The heat sink acts as an area extender, making it even easier for heat to leave the top of the component and to be carried away by the air. Introducing this design change reduces the BGA’s junction temperature rise by 70%, taking it well below its maximum safe operating limit. With the BGA running thermally compliant, let’s turn our attention to the TO-263 components.
Figure 4 is a Bn plot depicting the Bn distribution in the top signal layer of the PCB. We can see that, after adding the BGA heat sink, the largest thermal bottlenecks exist near the tabs of the two TO-263 devices. Recall that large Bn values do not mean this is the hottest area. Instead, the Bn figures and the plot reveal areas in which a lot of heat flows “downstream” from the heat source, and is highly restricted. Knowing exactly where the bottleneck is, a large copper pad can be added to cover that high bottleneck area, providing a targeted solution to a specifically identified problem. That is effective, efficient engineering.
Having made this modification, best practice methods call for an updated thermal simulation and inspection of the new Bn and Sc distributions. Figure 5 shows Sc on a cross-section through one of the two TO-263s after the addition of the copper pad. The expanded inset view shows large Sc values on the signal layer and the power and ground planes below the new copper pad and TO-263 tabs, indicating a shortcut opportunity between these layers. This agrees with a designer’s intuition, since heat spreads readily in the metallic layers of the PCB, while the dielectric’s low thermal conductivity acts as an effective barrier to heat transfer. Adding thermal vias to create a new heat transfer path down to the buried ground plane is an excellent, practical way to take advantage of this shortcut opportunity. Note that the Sc field pinpoints exactly where the thermal vias should be added for maximum effect.
By examining the Bn and Sc variations in and around the TO-263, the exact shape of the copper pad and the location of an array of thermal vias (shown schematically in Figure 6) can be determined quickly, without resorting to numerous “what if” studies. In this case, adding the pad and vias yielded a 30% drop in the temperature rise of the TO-263 devices, again taking them below their maximum rated temperatures.
The Bn and Sc fields together provide invaluable insight and comprehension about temperature distribution and behavior in an electronics system. By detecting and mapping both thermal constrictions (bottlenecks) and potential shortcuts for more efficient heat transfer, these parameters enable engineers to quickly determine the most promising thermal design changes – those most likely to provide the most efficient, effective results – without years of thermal experience and intuition. In the example, three Bn- and Sc-inspired thermal design changes were identified quickly, and the resulting “fixes” dramatically reduced the temperature of the three overheating components discovered in the initial simulation. It is an approach that delivers important gains in simulation productivity. Rather than simulating all possible remedial actions for thermal problems and choosing the best one, engineers can see immediately where they need to focus their thermal design effort.
Byron Blackmore, John Parry and Robin Bornoff are with Mentor Graphics’ Mechanical Analysis Division (mentor.com); This email address is being protected from spambots. You need JavaScript enabled to view it..
The second of a two-part series looks at how timing and PCB trace lengths affect different real systems, and design tricks for tuning timing.
On topology diagrams, we can easily visualize or specify the delays between any driver/receiver pair on multi-point nets. Some standards specify PCB design rules this way, for example, DDR-SDRAM DIMM memories (various Jedec JESD21-C documents) or Chipset Design Guides. Some design programs specify the constraints on these diagrams, like the Cadence Allegro Signal Explorer. The topology may be defined graphically, or as a spreadsheet for the point-to-point min./max. or relative length rules.12
Add-in cards: If a bus is routed through multiple boards, then the timing and length rules have to be correct for the whole system together (Figure 20). If different individuals or companies design the boards, they have to agree in the way of dividing the constraints between the boards, as a form-factor standard. In case of a clock tree, if the add-in card clock trace length is closely the same for all cards, then the skew can be controlled only by the motherboard design.
To control the ref./data signal arrival times at the capture flip-flop, control the delays on PCB traces. If two signals have similar drivers and trace lengths (matched), then the propagation delay and the transition delay also will be very similar, and propagation delay matching ensured by simple trace length matching.
The PLL (Phase-Locked Loop, on-chip device) can be used on continuously running clocks to introduce phase delays, negative delays or frequency multiplication. PLLs usually contain some kind of modifier element in their feedback loop. If this modifier element is a frequency divider (by M), then the PLL will generate an output clock, which has a frequency of M*f_in. If the modifier is a DF phase delay element, then the PLL inputs will be DF delayed from the output, so the output will be 360°- DF delayed from the input. If we have a PCB trace as the modifier element, then it will cause the inputs to be late by t_pd comparing to the output, so it looks like if the output was delayed by –1*t_pd from the input.
The DLL (Delay Locked Loop, on-chip device) is a fixed or adjustable delay element. It has “taps”; each tap has a unit delay value. The number of taps connected into the signal path determines the DLL delay.
To maintain the best timing for all on-chip data paths, the chips contain clock networks as balanced trees, so the clock will arrive to each flip-flop within a tight t_pd range. Normally there is an option to place a PLL before the clock tree to achieve zero clock propagation delay through the clock network. In some I/O applications, it might be useful, for example, if the clock network delay is a lot longer than the data path delay.
On bidirectional buses, minimize the clock skew between all the chips. If the clock is generated inside one of the chips, then the clock propagation delay to that chip would be zero, while to the other chips it would be based on the on-board routing. To avoid that, we introduce the same clock propagation delay to the chip generating the clock, by using the feedback clock. This simply routes the clock back to the same chip. A data path with a certain delay in it can be divided into two separate paths by inserting a register or flip-flop into it. Both parts will have the same available time for signal propagation as the original path had, but with only a part of the original delay. Note that the data will arrive one bit time or one clock cycle later to the final capture flip-flop, but it will be captured with better timing margins. This technique is usually used on high-speed on-chip data processing, and on registered DIMM (RDIMM) memory card designs.
Usually the DLL/PLL delays are controllable, and we can also insert register stages in the datapath. These can be fixed by chip design or can be software programmable, but in most of the cases, they are adjusted automatically by a state machine. Examples are the DDR3-SDRAM memory Read and Write Leveling features.2
On-Chip Timing Design
Some of the above methods are really chip-design methods. The chip or ASIC/FPGA designers have to design their I/O interfaces to be operational with realistic board design. To achieve this, they set up timing constraints, use guided logic placement or floorplanning, do careful chip pinout design, use DLLs/PLLs, use localized high-speed IO clock networks, use asynchronous FIFOs and design clever architecture for backend data paths.8,11,13
The different devices in synchronous systems use the same clock source to run their I/O and on-chip flip-flops. There is always one clock generator, and its output is distributed to every device on the same bus. If the bus is bidirectional, then the best way to balance the read/write setup/hold margins is to balance/match the clock propagation delays. If there is a clock skew between two chips, then one of the margins is decreased by the value of the clock skew. The clock skew may be known as uncertainty (peak to peak), or as an absolute value (with a sign).
DDR-SDRAM memory interfaces have source-synchronous data buses (lanes), and they have a unidirectional synchronous address/command/control (ACC) bus. We have two types of implementations: the DIMM socketed card, and the Memory-Down, where the chips are soldered onto the motherboard. Either designing a DIMM card or a memdown, we usually follow the layout design rules specified in the appropriate card type from the JEDEC JESD21-C standard.2,9,12
The data bus timing is valid in every lane separately between the DQ/DM and DQS strobe signals. The DQS path has a DLL delay in the memory controller chip, so the DQS is delayed before entering to the PCB for write transactions, while for reads it is delayed only after it has arrived onto the controller chip.
The address/command/control (ACC) bus is sampled by the memory chips at the rising edges of the clock signal provided by the memory controller. In case of 2T clocking mode, every second rising edge is used to sample the ACC bus. The ACC bus is routed to every memory chip in a memory channel, so it can have a very heavy loading, which creates very slow transition delays. If the load is above a certain value, then we need registered/buffered DIMM memories. DDR1 and DDR2 standards use balanced-tree clock/ACC topology to make sure all chips get the clock/ACC in the same time, while DDR3 uses the Fly-By topology to minimize SNN and to have only one end where we can terminate them.
Reference-Reference Timing
Although the main I/O matching is between the data-strobe and the clock-ACC, there are also clock-to-strobe design rules. These are based on the chip timing design behind the I/O flip-flops.
The memory chips expect the first valid databit to arrive a certain time after they have captured a write command. The controller puts the first databit to the bus with the right timing, but the board design has to make sure that this timing is still maintained when the signals arrive to the memory. This requires a length matching between the clock and the strobe signals. For this, there is an output guaranteed skew timing parameter from the controller data sheet, and an input maximum skew parameter from the memory chip data sheet. This input parameter of the memory is the t_DQSS, which is +/- t_clk/4, between the rising edge of the clock and the rising edge of the DQS signal. They also specify a clk-rising to DQS-falling-edge input rule, which is the t_DSS and the t_DSH parameters together. For DDR3 memories, the write leveling feature can compensate for this.
The memory controller has to pass the captured data from the DQS clock domain to the internal clock domain. This clock domain crossing requires the data to arrive to the controller within a specified time window. This limits the maximum length of the bus, since if the bus is longer, then the data arrives later, decreasing the setup margin in the backend flip-flops. The memory chip data sheet specifies the maximum skew between the input clock and the output DQS, as t_DQSCK. The controller data sheet specifies a maximum skew of the output clock and the input. Both the clock and the DQS trace lengths increase this.
Some FPGA implementations handle this by calibrating the delay with DLLs and registers for all the read DQ/DQS signals.9
Timing calibration. We can include delay circuits in the DQ/DQS paths. These can be fixed, or adjusted by a hardware state machine or by software to achieve optimal timing. For example, if we extend the delay of a reference signal to t_clk, then the effect is like if the reference signal was not delayed at all (in the aspect of STA), although the controller has to expect the data in the next cycle (in the aspect of protocol). The board/chip delays are mostly static for a given board, although they vary between boards and over temperature. That is why we calibrate after power-up. We can measure signal quality by adjusting DLL delays step-by-step, capturing the data and seeking for the DLL value where the captured data is different than in the previous step. This way we can find the boundaries of the Data Valid Window. Then we can set the final delays in the middle of the region.
Write leveling. This process compensates for the clock-to-strobe matching issues, and skew caused by the fly-by ACC topology. The controller puts the memory chips into write leveling mode. Then the memory will sample the CLK using DQS edges; then it sends the captured value to the controller on the DQ0 line. The controller finds the two DLL values where the sampled value changes, then sets the DLL half way.
Read leveling. This process balances the data bus read setup/hold margins by adjusting the DQS delay. In read leveling mode, the controller writes a fixed test pattern into the general purpose register in the memory, reads it back again and again, seeking for the minimum and maximum delays where it can still read the correct data. Then it sets the DLL half way.
All DQ/DQS DLL calibration: FPGA-based memory controller implementations can have a separate DLL on each data line. This way we can compensate on-chip for board/chip mismatch.9
Arbitrary examples. In Compact-PCI systems, a single board computer may be in a system controller or in a peripheral slot. In system controller mode, it has to supply the clocks to all other cards, and in peripheral mode, it has to take the clock from the backplane to clock its backplane I/O circuits. In both cases the clock signals have to be matched with a given tolerance. The system controller slot has 3 to 7 clock output signals, each routed to a different peripheral slot on the backplane with a length of 6.3"+/-0.04". The peripheral cards have to route this clock to their backplane interface circuits with 2.5"+/-0.04" length.
The MB86065 D/A Converter from Fujitsu receives the data as LVDS differential signals from the host (e.g an FPGA), and provides the I/O bit clock to the host. The DAC requires the data and the clock to be in phase + 90° at the DAC pins. The trick is to use a PLL feedback net on the PCB with a delay equal to the clock+data length on the PCB, creating a negative delay for the launch flip-flop. The PLL needs to have a 0° and a 90° output: the 0° for the feedback loop, and the 90° for the launch flip-flop for the extra alignment. This interface is a unidirectional synchronous interface, but the clock is provided by the receiver chip.14
When multiple lanes are used in the high-speed serial interfaces, in the receiver chip each lane has its own CDR (Clock-Data-Recovery) circuit, so each lane’s SerDes will clock its parallel output with a different clock. These have a phase relationship based on the lane-to-lane skew on-board and on-chip. The parallel data are passed to the core clock domain. If that clock domain is derived, for example, from Lane-0 clock, then it will capture the Lane-0 parallel data with proper timing, but the other lanes will be early/late by the lane-to-lane skew. This is usually handled by a clock-DLL for lower speeds or by using asynchronous FIFOs for each lane. In case of a DLL, the max lane-to-lane skew is defined by STA at the clock domain crossing. In case of FIFOs, the maximum lane-to-lane skew is limited by the FIFO depth and the protocol. Some protocols define FIFO under/overflow control by transmitting align characters. The max skew can be t_skew < N * k * t_bit_serial, where they use “k” bits per symbol, and “N” is half the portion of FIFO depth allocated for deskew.12
Calculating PCB Trace Length Constraints
Trace length constraints can be calculated from the timing margins of the pre-layout timing analysis. These constraints are specified to ensure certain propagation delays. For multi-point buses, define pin-to-pin delay rules, or rules for “all pin pairs.” Sometimes the signal travels through a series element: for example, a damping resistor or an AC coupling capacitor. The design program has to be able to measure the pin-to-pin lengths even in these cases.
Specify min./max. absolute or relative (matching) trace propagation delay or trace length rules, depending on the interface type. For the absolute data signal lengths, consider an already specified (by floorplanning) or routed reference signal length. Matching rules cannot be used for them, since the matching offset+tolerance would depend on the reference signal’s length. The relative constraints for data signals specify trace length difference from the reference signal. For them, the reference length need not be specified in advance.
The min./max. data propagation delay can be derived directly from timing margins, since the margins have been calculated using t_pd_data = 0 for absolute rules, or delta_t_pd = 0 for relative rules. Transform the smaller of the RD/WR margins to t_pd by checking what would cause zero margin. If the t_pd_data is a degrading parameter, then transform t_SU_MAR => t_pd_data_max. If t_pd_data is an improving parameter, then transform the -1*t_H_MAR => t_pd_data_min. In case of timing graphs with existing propagation delays, increase/decrease any PCB trace by the above in the data path, or by the opposite for the reference path. If the two traces are on different types of layers, then they cannot be length matched; they have to be propagation delay matched. If a signal is partially routed on different layers, divide the t_pd for the two layers and calculate lengths separately.
For chips in bigger packages, like x86 chipsets or large FPGAs, the manufacturer provides “package length” information. This is a spreadsheet of routing lengths inside the package for every signal pin. For board design, the package lengths have to be included in the total length. For example, the Cadence Allegro PCB design software handles it as “pin delay.”
Length constraints also can be signal quality-based, for example, to minimize crosstalk, reflections, stub-length and losses. The crosstalk noise voltage and the insertion loss are proportional to the trace length, and are normally simulated as per-unit-length PCB trace parameters. The SI-based rules are much less sensitive to the exact length than the t_pd based rules.
We can simulate two parallel traces at a unit length to get the crosstalk as an S-parameter in dB, then considering the maximum crosstalk-noise voltage we would permit, calculate a maximum parallel-segment length:
Loss-based length constraints use the per-unit-length insertion loss at the signalling frequency:
Longer PCB traces have stronger inter-symbol interference as well, which affects propagation delays through the transition time increase. Differential-pair phase tolerance skew slows down the differential slew rate, closing the eye from the corners. If skew exceeds rise time, then it closes the eye from the sides as well.
Typical PCB Design Rules
Usually the reference path and data path are handled separately. Specify maximum clock skew (in case of a central clock source), or just calculate min./max. data length based on the already routed clock length (if the clock is supplied by one of the chips). To have all the constraints in advance, then based on the floor plan, the clock length can be specified that is the shortest possible but still easily routable and then its value set as a tight absolute length range. Then, use t_pd_clk_min./max. as input parameters to the timing margin calculations. The amount of clock skew (in case of a central clock source) tolerable can be calculated from a pre-layout timing margin with zero skew, and permit 10% of that margin to be clock skew.
Usual PCB design rules:
Min./max. data bus length.
Min./max. clock trace length or max clock skew.
An asynchronous interface also has min./max. absolute length rules. The reference signal is always supplied by the master chip. The design rules are min./max. trace lengths for the data signals based on predefined strobe trace lengths.
Usual PCB design rules:
Min./max. data bus length.
Min./max. strobe trace length.
Source synchronous systems are designed in such a way to ensure the data and reference signal (strobe) paths have similar delays on-board and on-chip, except the DLL inserted into the reference path. This means the goal is to keep the data signal length within a +/-delta_length window around the strobe trace length. This is the simplest to design, since we are not restricted to using a predefined reference length.
Usual PCB design rules:
Maximum strobe-to-data skew: as a relative length comparing to the strobe signal’s length. As speed increases, both the min./max. delta length values get closer to zero. In a usual DDR3 memory interface, specify a maximum 0.125 mm delta length.
The usual design constraint is “matching with an offset.” A simple explanatory equation can be derived from the generalized setup and hold equations: The data t_pd has to be roughly between the clock t_pd and the clock t_pd plus the clock period.
Calculate minimum and maximum length difference of the data signal trace length relative to the clock trace length. It will be asymmetric.
Usual PCB design rules:
Maximum clock-to-data skew.
Clock skew: If the clock generator is not inside the transmitter chip, then we have to balance the setup/hold margins with clock delay control.
Clock forwarding interfaces work in the same way as the unidirectional synchronous type, just that they support both read and write operations with separate clock signals for them.
Usual PCB design rules:
Maximum clock-to-data skew, separately for read and write.
The only trace length rules are signal quality-based and lane-to-lane matching rules.
First calculate min./max. propagation delays for the data signals based on the table below, then calculate lengths. Finally, apply some overdesign so after the layout has been designed, much greater-than-zero timing margins can be expected.
The source synchronous system timing can be handled in an absolute or in a relative way. The equations can be written in the same way as the synchronous systems, then the improving t_pd parameters changed to degrading parameters and multiplied by –1. After this, both the data and the reference t_pd will be degrading, sitting next to each other in the equations. Define delta_t_pd(+) = t_pd_data - t_pd_str, and replace the t_pd to these.
Steps for absolute rules: 1. Choose an absolute reference signal length (with a tolerance) or a maximum clock skew constraint. 2. Determine the reference signal t_pd from signal integrity simulation. 3. Determine the transition delay of the data signal using an estimated trace length. 4. Calculate all the timing margins, where the data signal t_pd is zero. Use t_pd_ref_min./max. as input parameters. If t_pd_clk is improving, then use minimum value, otherwise use maximum. 5. Convert the timing margins to min./max. t_pd for the data signals based on Table 2. 6. Calculate min./max. lengths for the data signals based on t_pd.
Steps for relative rules: 1. Calculate all timing margins, where the data signal and reference signal t_pd both are zero. 2. Transform the timing margins to min./max. t_pd for the data signals, relative to the ref.signal. 3. Determine the transition delays for both the data and the reference signal, based on estimated trace lengths. 4. Calculate min./max. delta_lengths for the data signals.
The length calculation. If the driver/receiver circuits of the data and reference signals are the same, then exclude the transition delay from the relative length calculation, since their transition delays will be near equal. This way their propagation delay matching is simplified to be trace length matching. If L_min > L_max or L_max < 0, then it is not possible to design a board at the given parameters.
Steps: 1. Get the transition delays at the receiver by a signal integrity simulation using estimated trace lengths, both minimum and maximum. 2. The propagation velocity (v) has to be calculated at the signalling frequency:
where c is the speed of light (3*10^8 meter/sec), Sr_eff is the effective dielectric constant of the materials surrounding the PCB trace.4 3. For absolute rules Length_min = v * (t_pd_min – transition_delay_min) and Length_max = v * (t_pd_max – transition_delay_max). For relative rules delta_Length(+) = v * (t_pd_max - transition_delay_data + transition_delay_ref) and delta_Length(-) = v * (t_pd_min - transition_delay_ref + transition_delay_data). Use min transition delay for maximum length, and maximum transition delay for minimum length, but only if the two signals are not driven by the same chip. Otherwise, both min. or both max.
The overdesign factor (OVDF). After calculating trace length constraints are ensuring minimum zero timing margins, make the system more robust by applying some overdesign. Here we introduce the Overdesign Factor (OVDF= {1.1…20}) for the tightening. Length_range = Length_max – Length_min Length_min_new = Length_min + 0.5 * Length_range * (1 - 1/OVDF) Length_max_new = Length_max - 0.5 * Length_range * (1 - 1/OVDF)
Transforming and summing constraints is simple algebra, but it might not be straightforward. To transform a min./max. length rule to an Offset+/-Delta, use the simple formulae:
Offset = (length_min + length_max)/2
Delta = length_max – Offset
The second case calls for merging two constraints. For example, the chipset design guide provides direct trace length rules for interfacing a DIMM memory to the processor, and we want to design a memory-down layout based on JESD21C guidelines. In such cases, transform both constraints to Offset+/-Delta description, then sum the offsets and deltas separately.
Conclusions
High-speed digital board design requires control of the trace lengths pin-to-pin on multipoint signal nets. To achieve this, software supports detailed complex trace length constraints. Sometimes designers can use standard trace length rules specified by chip manufacturers or standards, while other times they calculate them from pre-layout timing analysis. If the board designer did not use proper length constraints, the boards may never even start up in the lab. Often, timing parameters for the chips on the board are needed, but just not available. In those cases, timing parameters defined at package-pins can be used. What the post-layout timing analysis reveals is not whether the prototype board will start in the lab, but if it will operate reliably in the field at all times. If this verification is absent in product development, the risk is untraceable errors in products will be detected by customers.
1. J. Bhasker and R. Chadha, Static Timing Analysis for Nanometer Designs, Springer, April 2009. 2. JESD79-xx, “DDR-SDRAM Memory Standards,” www.jedec.org 4. Dielectric Constant Frequency Compensation Calculator, buenos.extra.hu/iromanyok/E_r_frequency_compensation.xls. 9. Xilinx DDR-SDRAM controller application notes: XAPP858, XAPP802, xilinx.com/support/documentation/application_notes.htm. 11. David Robert Stauffer et al, High Speed Serdes Devices and Applications, Springer, October 2008. 12. Jedec, JESD21-C, “Jedec Configurations for Solid State Memories,” jedec.org. 13. Steve Kilts, Advanced FPGA Design, Wiley-Interscience, March 2006. 14. Xilinx DAC/ADC interfacing application notes, XAPP873, XAPP866.
Istvan Nagy is with Bluechip Technology (bluechiptechnology.co.uk); This email address is being protected from spambots. You need JavaScript enabled to view it..